
背景:額度有限,但品質不能妥協
用 AI 寫程式已經是很多開發者的日常,但很快就會遇到一個現實問題:
好模型額度貴,便宜模型又常常亂跑。
一個直覺的解法是:讓強模型負責「思考」,讓便宜模型負責「實作」。
這個概念被稱為「分層 AI 開發流程」,目前已有不少團隊在實踐。這篇文章會帶你完整理解這套流程的邏輯,以及最關鍵的一點——你的專案到底適不適合這樣做。
核心概念:分層分工
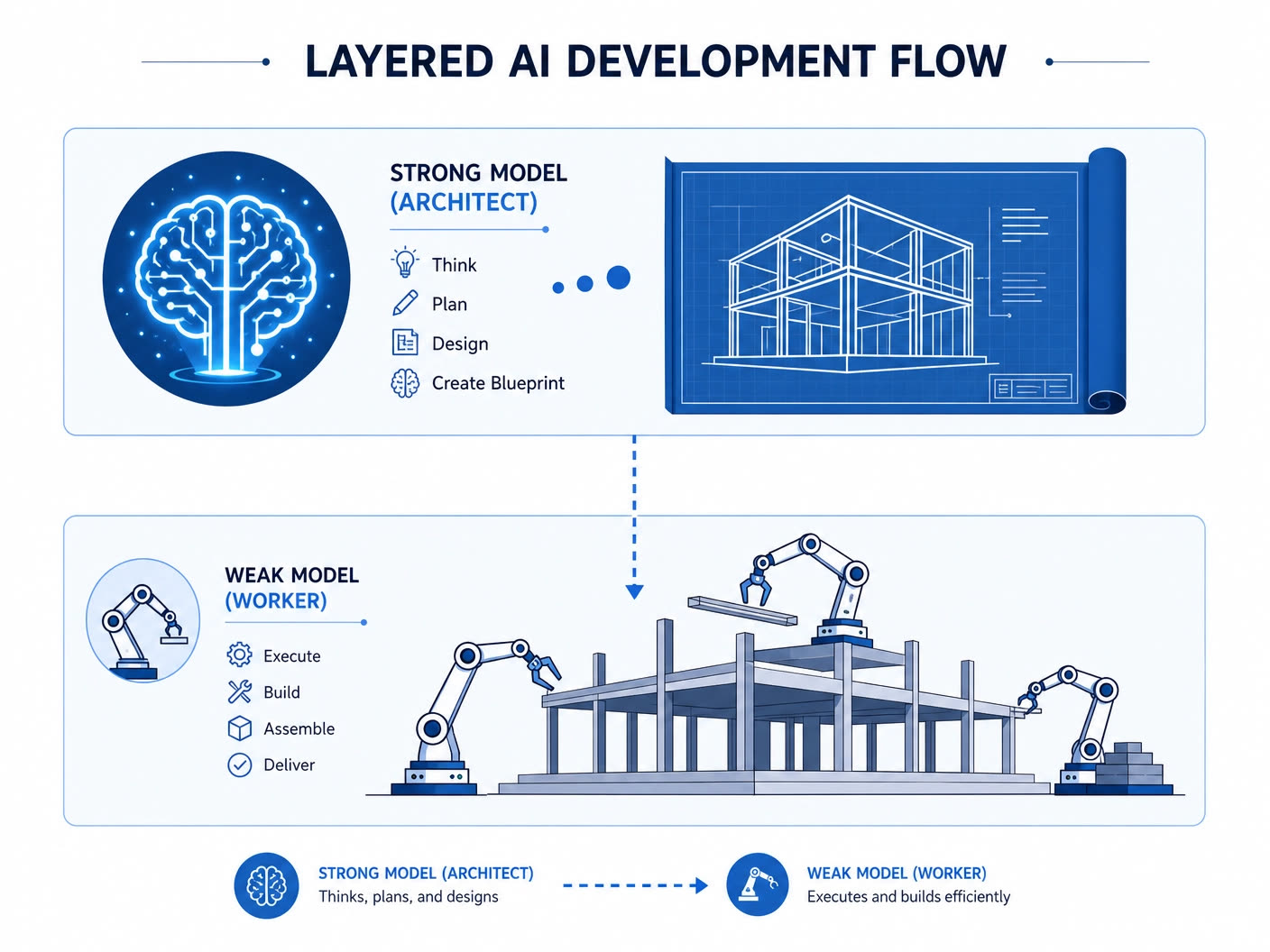
| 角色 | 負責什麼 |
|---|---|
| 強模型(如 Claude Opus、GPT-4o) | 思考、架構、規格、Edge Case |
| 便宜模型(如 Claude Haiku、GPT-4o mini) | 實作、重複性產出、樣板 code |
關鍵前提是:
便宜模型最怕的不是「寫不出來」,而是「搞不清楚要寫什麼」。
只要把決策空間縮小,便宜模型的輸出品質會穩定很多。
三個階段的實際做法
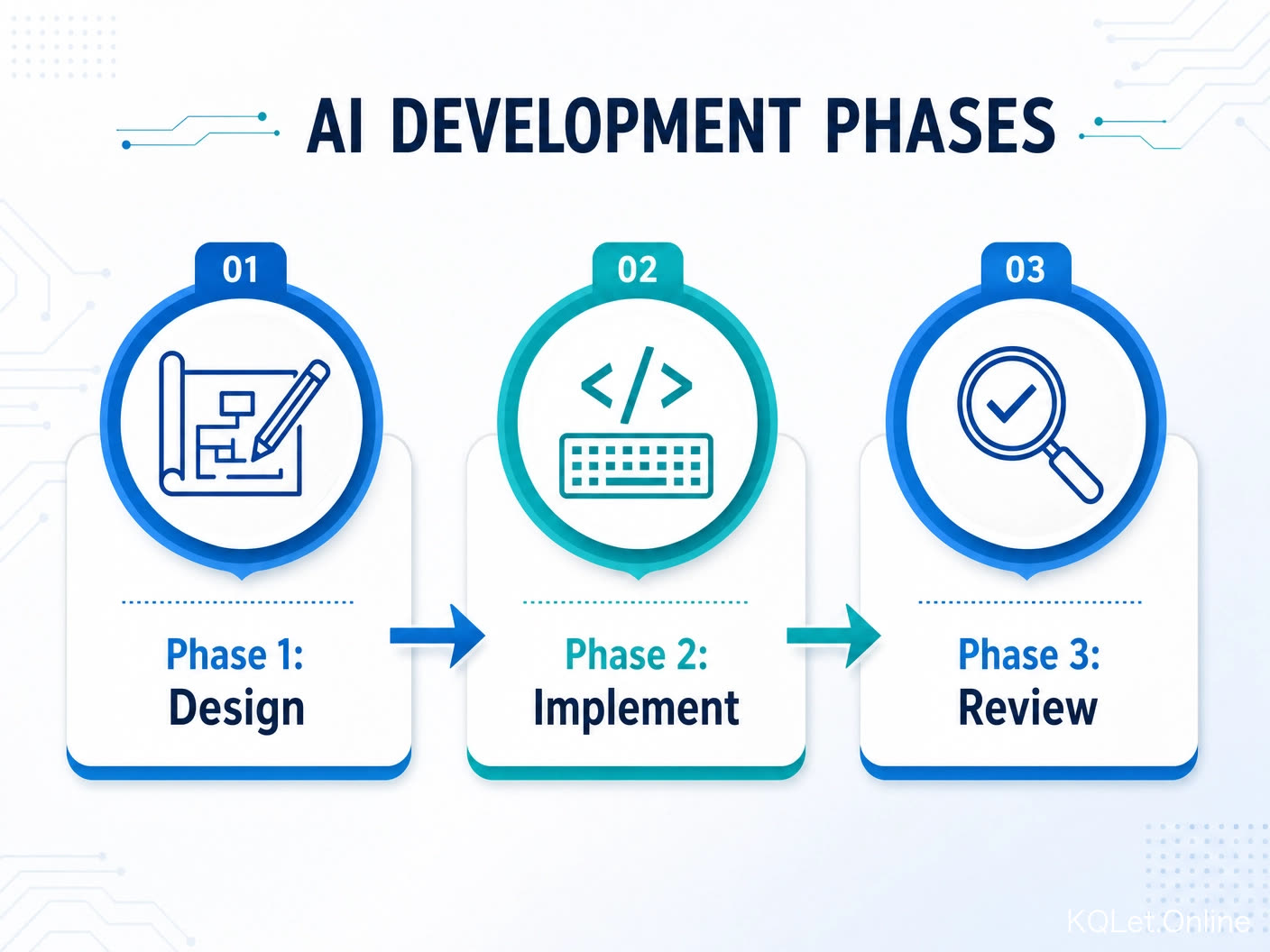
Phase 1|強模型:設計與規格
不要直接叫強模型生 code。讓它輸出:
- 資料流(Data Flow)
- Type / Interface 定義
- 模組切分方式
- Edge Case 清單
- Pseudo Code
- Unit Test 規格
這一步的目的是把「需求」轉換成「高訊號的結構化上下文」。
Phase 2|便宜模型:依規格實作
給便宜模型的 prompt 要帶上 Phase 1 的產出,並加上明確的限制,例如:
請嚴格依照以下 Pseudo Code 實作,不可自行改動 architecture,
缺少資訊時才提出問題,保持 naming 一致。
[貼上 Pseudo Code 與 Interface]這會讓模型進入「受限生成」模式,錯誤率與重工率都會下降。
Phase 3|強模型:Review
只 review 關鍵點,不要重新生成所有 code:
- Bug 與邏輯漏洞
- Edge Case 有沒有被覆蓋
- Security 問題
- Performance 瓶頸
- Readability
這一步的 token 消耗會遠低於「從頭再生一次」。
Pseudo Code 的真正價值:不是假程式碼,是壓縮上下文
很多人以為 Pseudo Code 只是一種「說明文字」,其實它是在做一件更重要的事:
把設計意圖、業務邏輯、執行順序,壓縮成便宜模型能直接使用的高密度上下文。
舉個例子,與其這樣描述:
請做一個查詢用戶資料的 API,要有快取不如給出這個:
1. validate input (userId format)
2. cache lookup → if hit, return cached DTO
3. db query by userId
4. if not found, throw NotFoundException
5. map entity to DTO
6. set cache (TTL: 300s)
7. return DTO便宜模型看到第二種,function 切分、flow、naming 全都固定了,它只剩「翻譯成 code」這件事,幾乎不會亂跑。
比 Pseudo Code 更有效的三種做法
Pseudo Code 很好,但有些情況下這些東西更有效:
1. Interface First
直接定義型別,比文字描述精確得多:
interface AuthService {
login(email: string, password: string): Promise<AuthResult>
logout(userId: string): Promise<void>
refreshToken(token: string): Promise<TokenPair>
}2. Example Driven
給定 input / output / error case,AI 的輸出會非常準:
input: { userId: "123", amount: -50 }
expected output: ValidationError("amount must be positive")
input: { userId: "123", amount: 100 }
expected output: { success: true, balance: 900 }3. Test First
先讓強模型生 unit test,再讓便宜模型依照 test 實作。這對便宜模型特別有效,因為行為被固定,歧義大幅下降。
⚠️ 注意:便宜模型寫的 test 要小心,它很容易寫出「只讓 test 通過」而非「真正驗證行為」的測試。Unit test 初稿交給便宜模型 OK,但要人工或強模型審查過。
最省額度的通用原則:降低 AI 的決策自由度
最浪費 token 的 prompt 是:
請幫我做一個 XXX因為 AI 要同時做:理解需求 → 推理架構 → 做決策 → 命名 → 實作。
最省的方式是把這些決策提前做好,只讓 AI 做「翻譯」:
需求描述
+ 限制條件
+ 檔案結構
+ Pseudo Code
+ Interface
+ 現有程式碼片段決策越少,成本越低,錯誤率也越低。
哪些地方值得花強模型額度?
| 值得用強模型 | 交給便宜模型 |
|---|---|
| DB Schema 設計 | CRUD 實作 |
| API Contract 定義 | DTO / Mapping |
| 系統架構決策 | Validation 邏輯 |
| Concurrency / Cache 策略 | 樣板 Boilerplate |
| Security 設計 | Unit Test 初稿 |
| Migration 計畫 | 重複性產出 |
| Edge Case 分析 | 文件初稿 |
如何判斷你的專案適不適合這套流程?
這套流程不是萬用解,以下是實際判斷方式:
✅ 適合的情況
1. 需求相對穩定 如果需求會頻繁大改,Pseudo Code 也要跟著重寫,分層的效益會大幅下降。適合的情境是:需求已經明確、只是實作量大。
2. 重複性工作多 CRUD、API endpoint、DTO mapping 這類工作高度重複,正是便宜模型最擅長的。如果你的專案大量是這類工作,效益明顯。
3. 你有能力審查輸出 這套流程的前提是你能判斷「便宜模型的 code 有沒有出錯」。如果你是初學者、對 code 審查沒把握,這套流程的效益會打折,因為省下的錢可能花在 debug 上。
4. 開發週期長、迭代次數多 一次性的小腳本不值得分層。但如果是持續維護的系統,前期投資架構設計的回報率很高。
❌ 不適合的情況
1. 探索性、研究型的工作 當你還在摸索方向、需要 AI 陪你一起發想時,強模型的「自由發揮」反而是優點,不適合限制它。
2. 需求模糊、快速驗證 MVP 先把東西跑起來比架構優雅更重要。這時候丟給強模型直接生,速度更快。
3. 任務本身很複雜、需要全程推理 有些問題(如:複雜的 concurrency bug、跨系統整合的 edge case)便宜模型根本無法在 Phase 2 正確實作,強迫分層反而增加來回成本。

🔍 判斷的核心問題:「這個任務的瓶頸在哪裡?」
| 瓶頸 | 建議 |
|---|---|
| 想不清楚要做什麼 | 先用強模型探索,再分層 |
| 知道要做什麼,但實作量大 | 適合分層 |
| 任務邏輯複雜,需要一路推理 | 全程強模型 |
| 反覆改需求 | 分層效益低,先穩定需求 |
一個簡單的自測:如果你可以在 15 分鐘內把 Pseudo Code 寫清楚,那這個任務很可能適合分層。如果連你自己都說不清楚流程,先別急著分層,用強模型幫你想清楚再說。
總結
分層 AI 開發流程的本質不是「哪個模型比較強」,而是:
怎麼降低 AI 的決策自由度,讓每個模型只做它最擅長的事。
Pseudo Code、Interface、Test Case 都是在做同一件事:把決策提前,把歧義消除,讓實作變成純粹的翻譯工作。
這套流程適合需求穩定、重複性高、你有能力審查的情境。遇到探索性工作或複雜推理,就不要硬套,直接用強模型更划算。
判斷的關鍵永遠是:這個任務的瓶頸在哪裡?
本文的發想來源於實際使用 AI 開發時遇到的額度限制問題,透過與 AI 的討論整理而成。